
The Domain Name System Runs on Open Source Software
Last week, ICANN published a report on the importance of open source in the DNS.
Read postIn the computer world, we commonly store temporary data in a cache to make programs run smoothly. A web browser has a local cache for storing web pages you've visited, and it also stores cookies in the local cache. CDNs store web pages in geographically diverse locations around the world for faster access. Recursive DNS servers are essentially just large caches wrapped in the DNS protocol. However, we never have unlimited memory available for caching, whether it's a purely memory-based cache or temporary data stored on a hard drive. Limited memory leads to a crucial decision: what to keep and what to discard. And that's where cache-eviction algorithms come into play. Their task is to preserve data that is most likely to be reused and discard data that won't be needed in the near future.
It's important to mention here that a key characteristic of cache-eviction algorithms is their simplicity. Complex algorithms may have better performance, but their diagnostics are much more difficult in the event of strange behavior. And since these algorithms are usually located in the so-called hot-path (i.e., a performance-critical area), more complex algorithms put more load on the CPU. It may happen that we achieve a better cache-hit/cache-miss ratio, but the overall performance will be lower.
I've included a basic overview here of only the most common cache-eviction algorithms. For a more detailed overview, you can refer to the Wikipedia article Cache replacement policies.
Bélády's algorithm is a purely theoretical concept that we can also call the clairvoyant algorithm. It's an algorithm that evicts items from the cache that will be needed the furthest in the future. However, since we don't have a crystal ball, this concept is only used when comparing the efficiency of algorithms that can actually be implemented.
This algorithm randomly selects items from the cache to be evicted. At first glance, this strategy doesn't seem like a good one, but it turns out that for some workloads, it may not be a bad choice.
These two simple algorithms based on a linked list indiscriminately evict items purely based on when they were added to the list. FIFO evicts items that entered the list first, so it works like a queue. LIFO, on the other hand, evicts items that entered the queue last, so it behaves like a stack.
As the name suggests, this cache-eviction policy evicts items from the cache that have been used the least recently. A simple LRU algorithm is implemented by adding new items (cache-miss) to the beginning of the list as long as there is space in memory, and existing items (cache-hit) are moved to the beginning of the list when accessed. When there is no more space to store new items, items are removed from the end of the list. LRU is actually a whole family of algorithms that always improve the original simple LRU algorithm in some way.
The family of LFU algorithms is based on counting the frequency of use of items in the cache. After the memory is full, the algorithm evicts items from the cache that have been used the least frequently. This algorithm is more suitable for some types of workloads, but it is more complex to implement.
SIEVE is a new cache-eviction algorithm that excels in its efficiency and simplicity. The implementation of SIEVE needs one queue (e.g., a linked list) and one pointer, which we call the hand. The queue maintains the order of insertion of items, and each item in the queue must contain one bit to indicate whether it has been visited or not. The hand points to the next candidate for removal from the queue and moves through the queue from the end to the beginning. If the hand is at the beginning of the queue, it moves back to the end if necessary.
Cache-hit. If the item already exists in the queue, it is simply marked as visited and the queue is not manipulated in any other way. If the item is already marked as visited, no change occurs.
Cache-miss. As new items arrive (cache-miss), the SIEVE algorithm always inserts them at the beginning of the queue. When there is no more space in the queue, the algorithm looks at the item pointed to by the hand. If the item is marked as visited, this flag is removed, and the hand moves to the previous item – as explained above, the hand moves towards the beginning of the queue. This is repeated until the hand points to an item that is not marked as visited. Then, this unvisited item is removed from the queue, creating space to store the new item in the cache. Although most of the removed items are located somewhere in the middle of the queue, new items are always stored at the beginning of the queue.
The whole algorithm can be nicely seen in the following picture (taken from the project's website):

Promotion and demotion are two basic principles for sorting items in the cache. It turns out that lazy promotion and fast demotion are two important properties of good cache-eviction algorithms. The principle of lazy promotion refers to the strategy of promoting items to be retained only when space needs to be freed in the cache. The goal is to preserve items with minimal effort. Lazy promotion increases throughput due to less need for computational power and efficiency, because we have more information about all items and their usage at the time when unnecessary items are discarded. Fast demotion works by removing items very quickly after they are inserted into the cache. The research linked above shows that fast demotion is also suitable for web caches. SIEVE is currently the simplest algorithm that implements both principles.
I do have to mention one disadvantage of SIEVE. The SIEVE algorithm is not inherently resistant to sequential scans, which makes this algorithm unsuitable for deployment in places where this is a frequent operation. Accesses generated by a sequential scan intertwine with popular objects, and the performance of SIEVE is worse in such a case than when using LRU. Marc Brooker on his blog provides a few ideas on how to deal with this when using SIEVE; using a small counter instead of a simple flag could allow SIEVE to be used in deployments where the cache is often scanned in its entirety.
SIEVE is a very simple algorithm to implement. Its initial implementation for BIND 9 took a very short time, and as a result, the cache code after removing the existing cache-eviction mechanisms in BIND 9 and replacing them with SIEVE is altogether leaner by more than 300 lines.
The basic implementation of LRU always moves items to the end of the list on a cache-hit. In multi-threaded programs this means that the entire data structure must be locked on every cache-hit (which should be mostly reads), which has a negative impact on performance. In practice, two techniques are commonly used, and BIND 9 implemented both of them – slowed update and LRU segmentation. It's not rocket science. Slowed update means that when moving an item to the beginning of the list, we note the time of the last update, and then we no longer update that item on subsequent accesses within a defined time window. LRU segmentation means that we have multiple LRU lists and each item has a fixed list assigned to it based on its characteristics, e.g., in the case of a DNS cache, items are assigned to individual lists based on the domain name under which they are stored in the cache. This approach doesn't work as well in the case of hierarchical data such as the DNS tree, where DNS names higher up in the tree are accessed more often, but it works fine in combination with delayed update.
Above, I said that the SIEVE algorithm, when it finds an existing item (cache-hit), only marks that item as visited. This has one major positive impact on performance: in the case of a cache-hit, the entire list does not have to be locked, but only consistent access to the above-mentioned flag needs to be ensured.
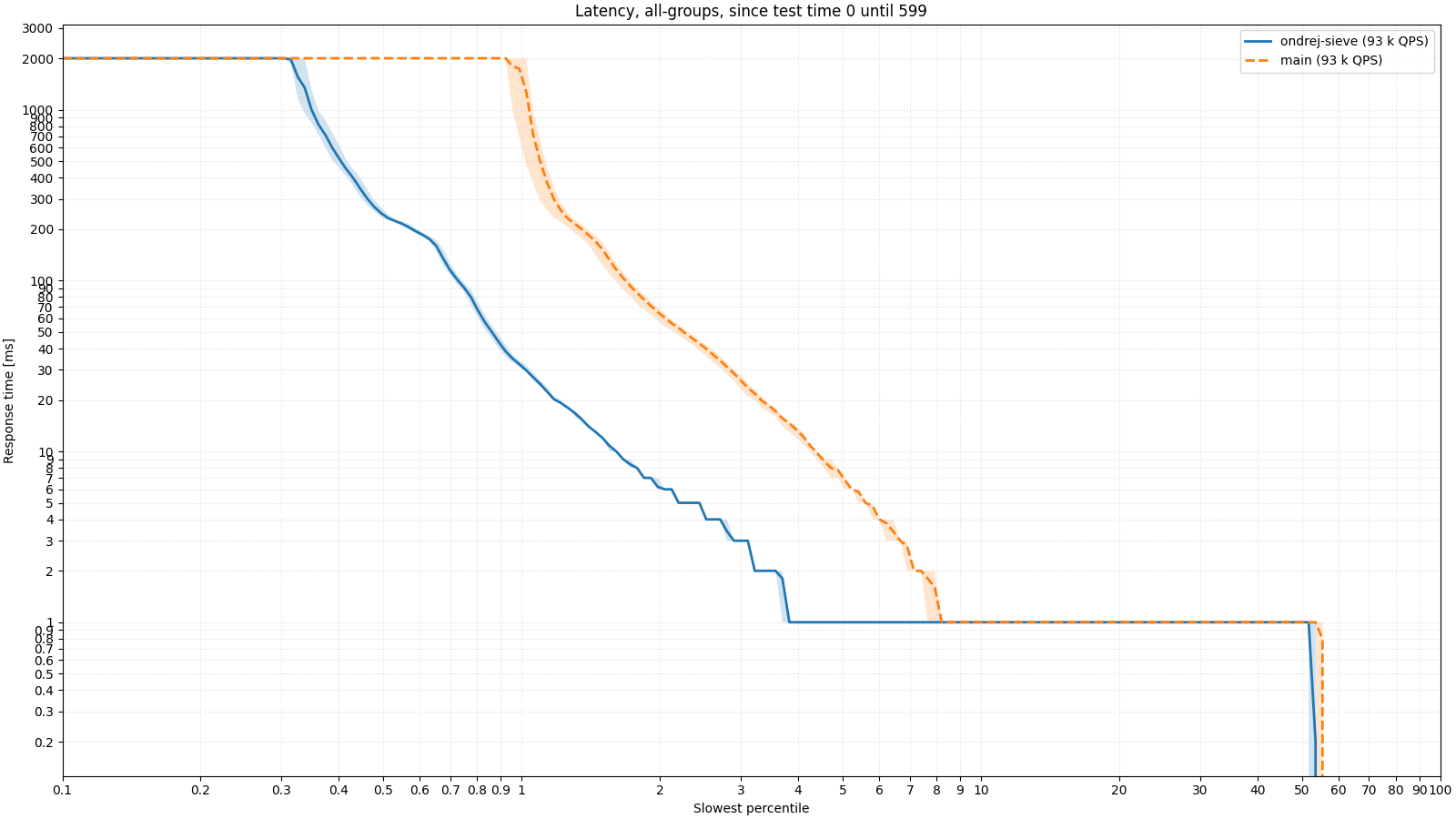
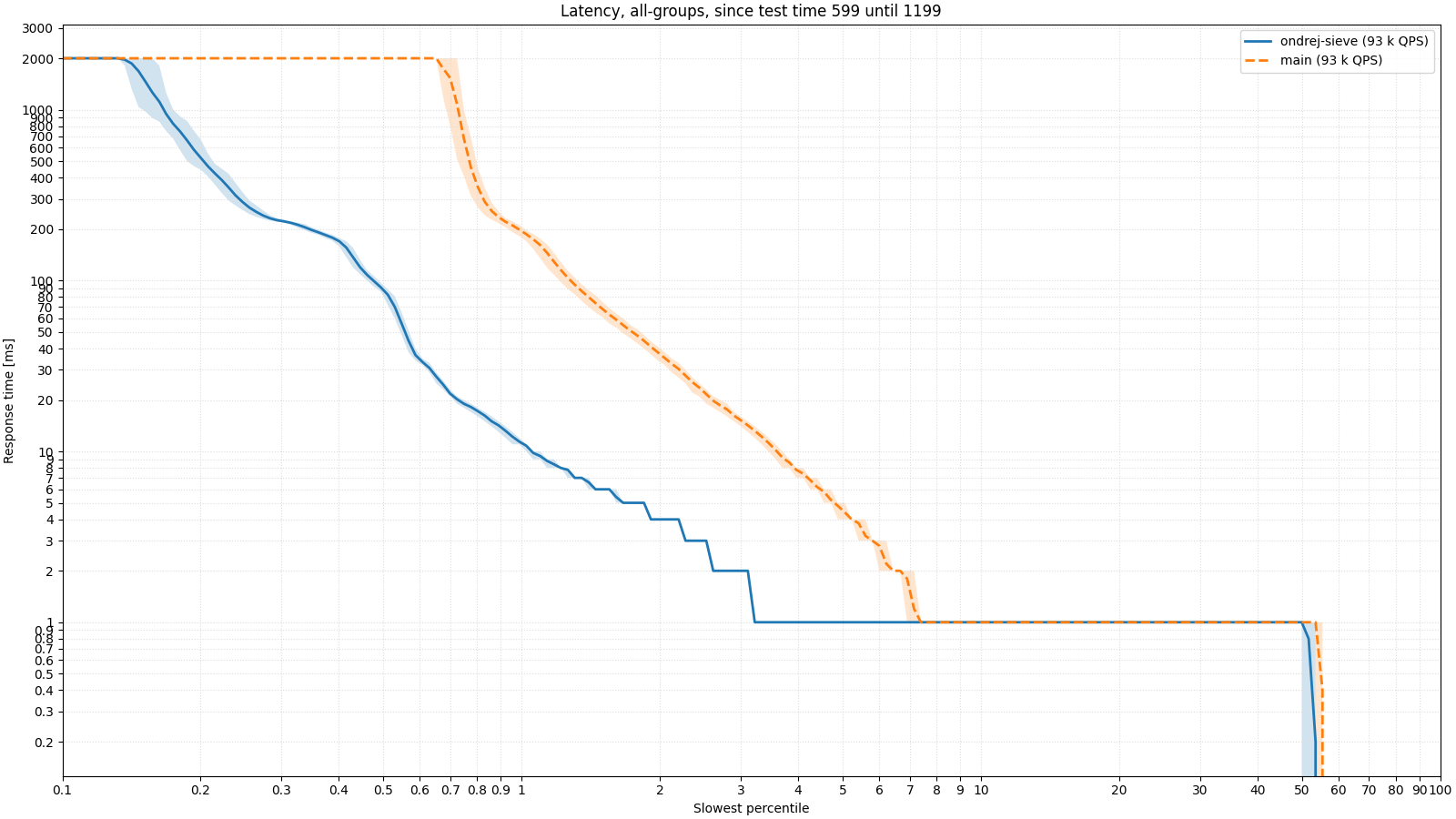
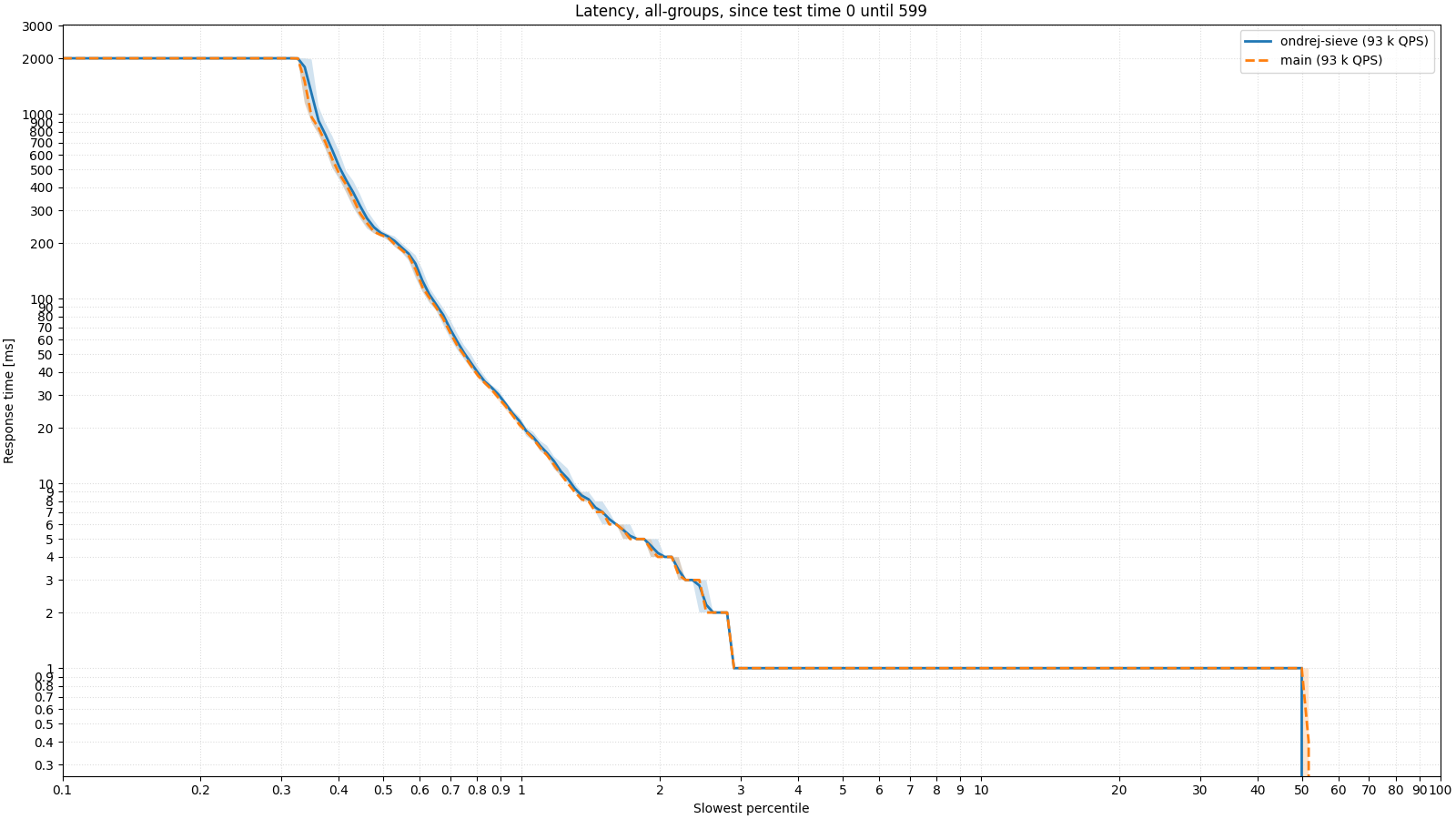
What does it look like in practice? I have prepared two tests of BIND 9 as a resolver, which run on real data provided by a telecommunications operator. In the first test, the resolver's memory (max-cache-size) is limited to 128 MB, which is a fairly small value, and the cache fills up quickly. The following image shows the latency of responses. We have already shown similar images in the previous article about BIND 9, but as a reminder, it is a logarithmic percentile histogram. Simply put, we want the measurement line to push as far to the left and as far down as possible, which means that the server responded as quickly as possible to as many responses as possible. The first image shows the latency in the first half of the test, when starting with an empty cache; the second image shows the second half of the test, where the cache is more or less full. It can be seen that especially in the case of a full cache, SIEVE behaves much better and the server is able to respond to more clients.
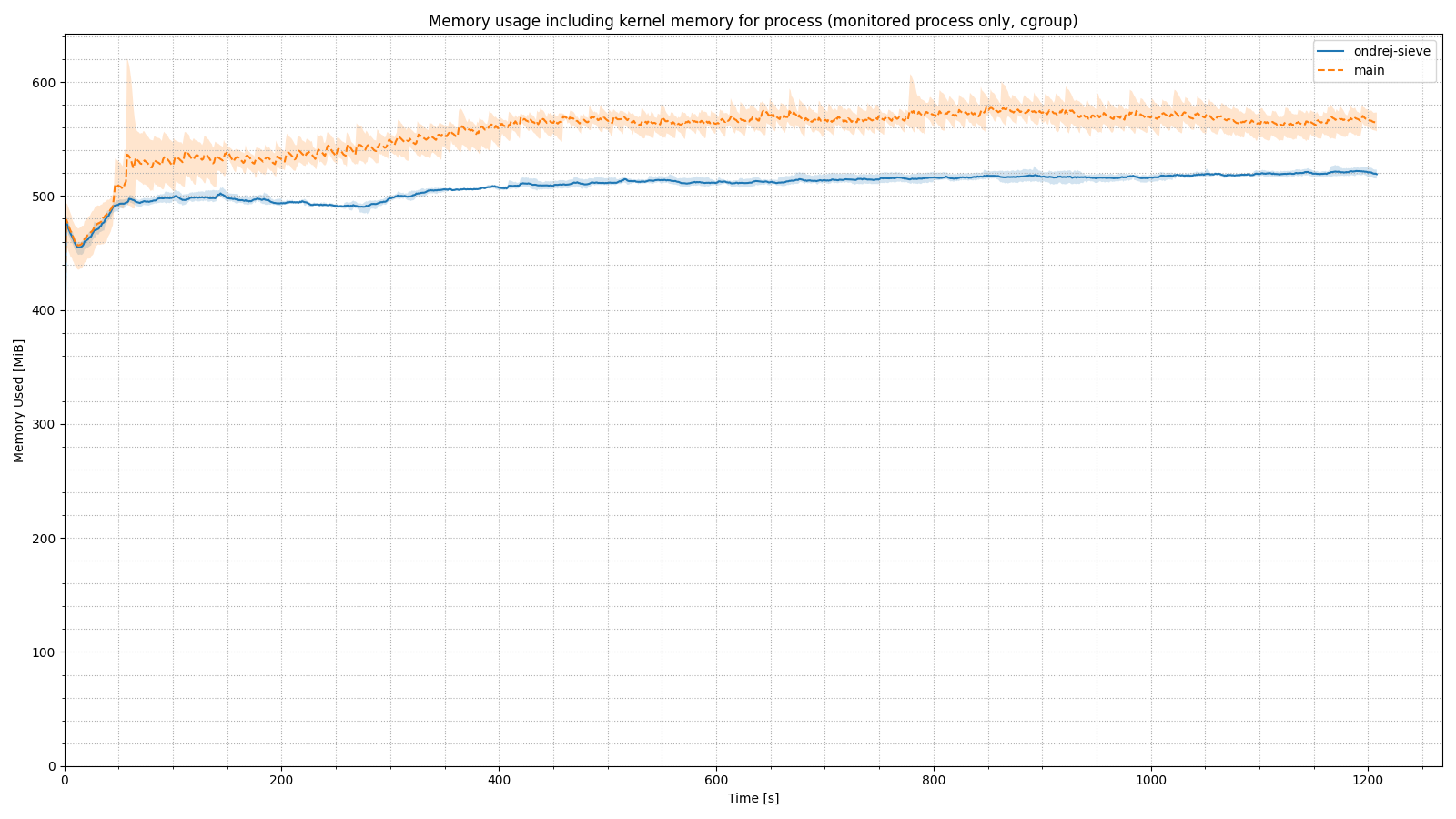
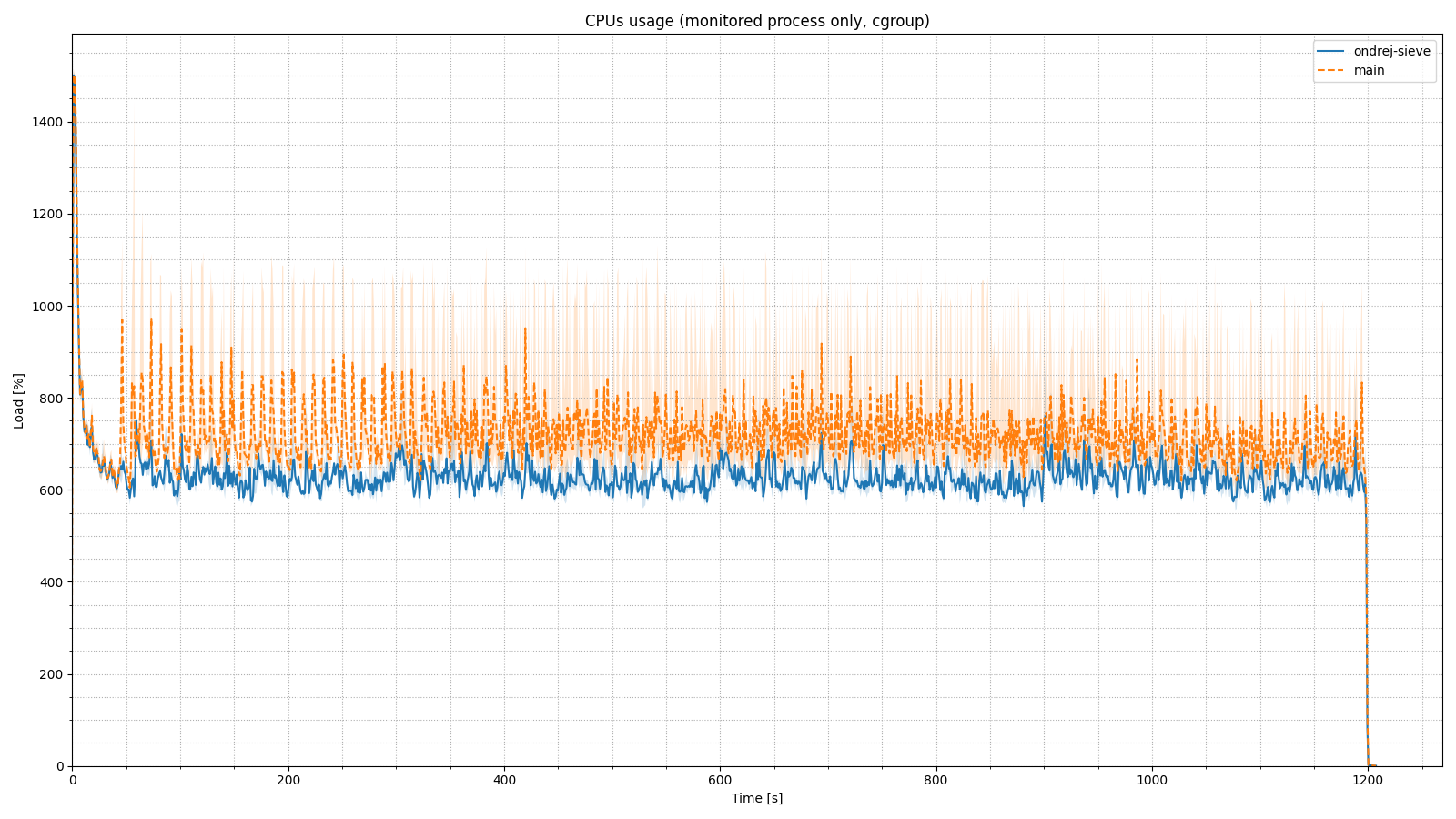
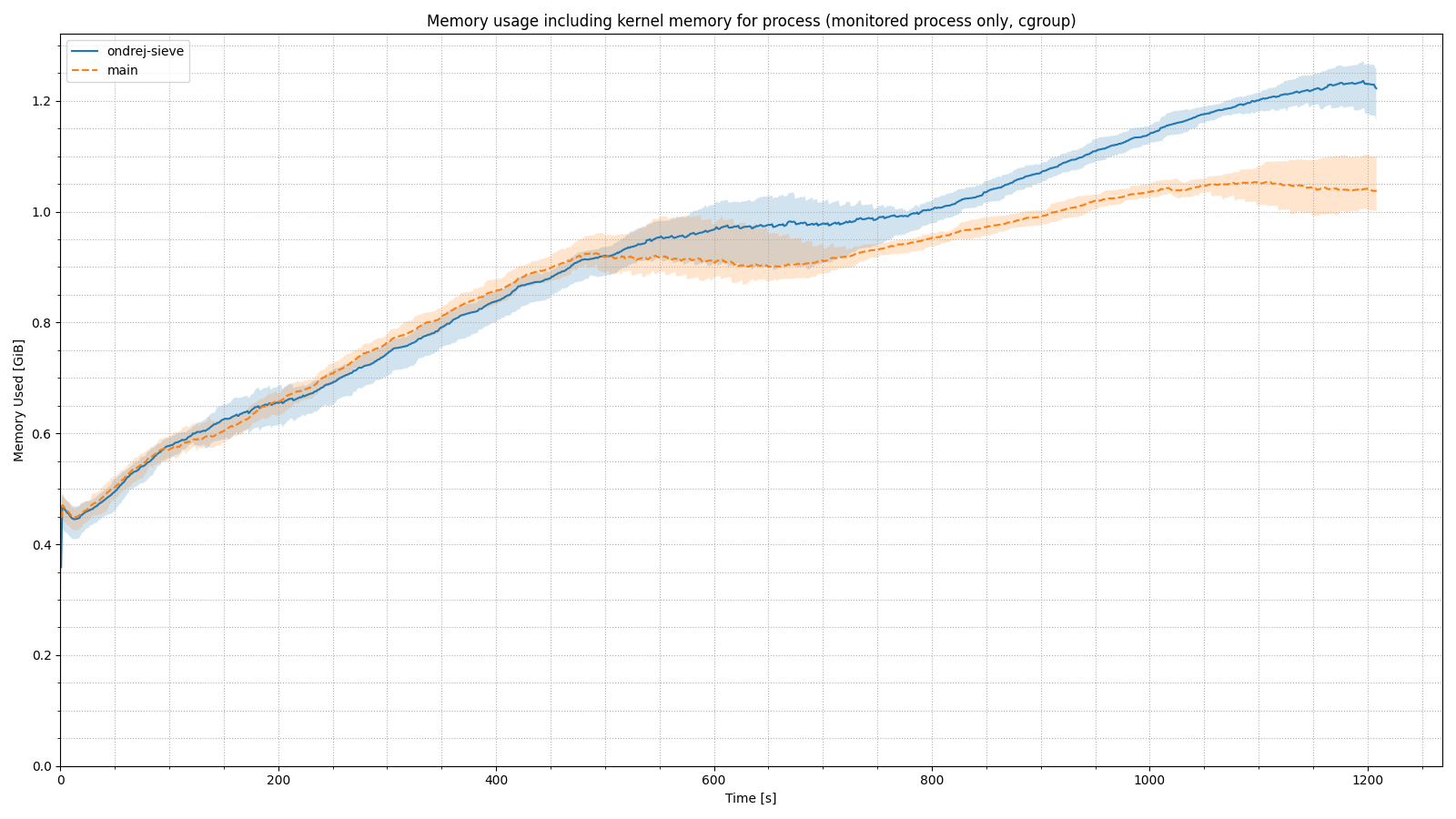
The next two graphs show the memory and processor usage over time. I think it is clear that the implementation of the SIEVE algorithm brought greater stability in memory usage under unfavorable conditions, and less load on the CPU.
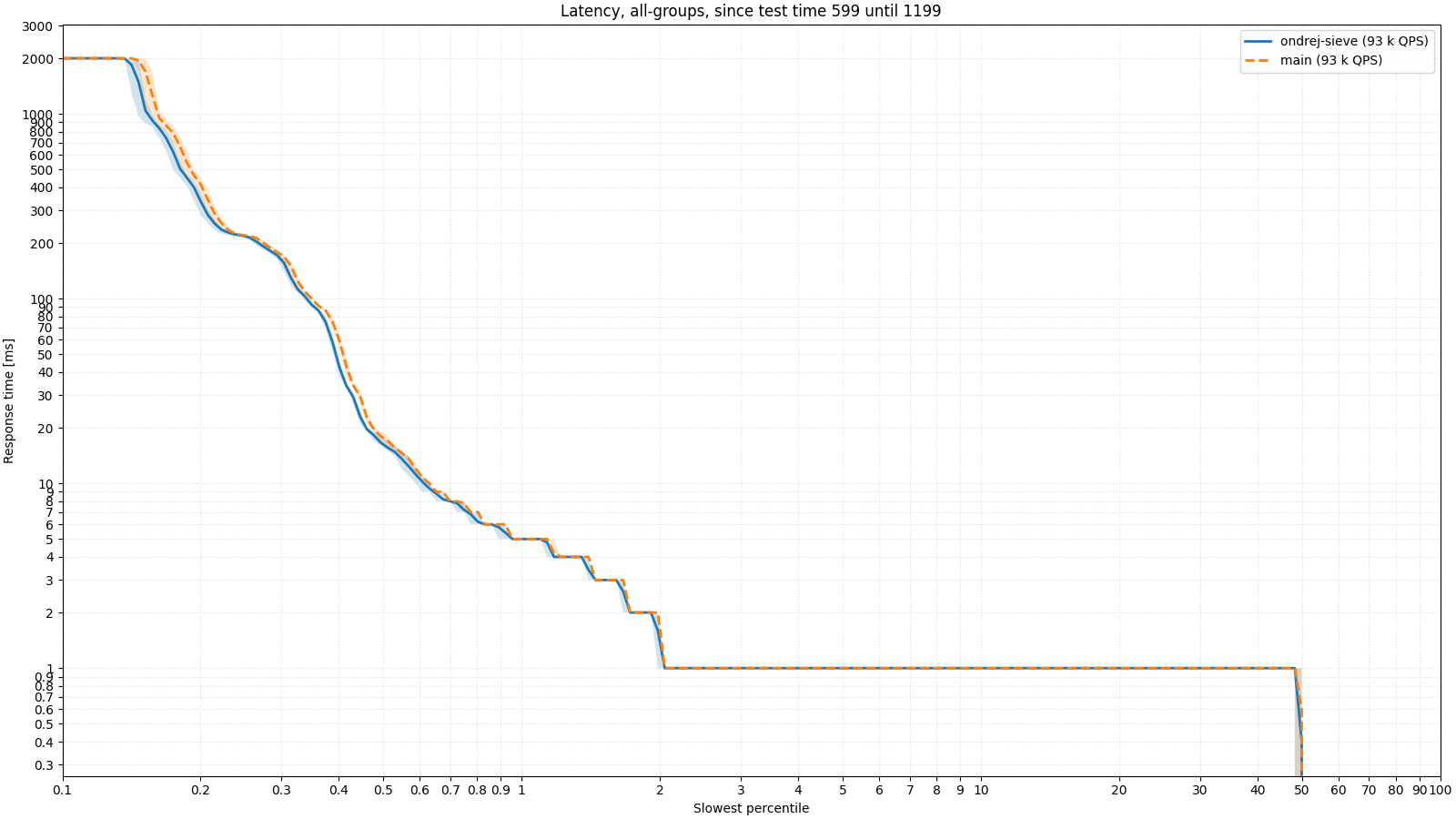
Current versions of BIND 9 use two memory-cleaning mechanisms. One is based on LRU and is only used if memory runs out. The second mechanism is more opportunistic and cleans items from the cache whose DNS TTL has expired. So what does it look like if we have enough memory for the cache and replace both of these mechanisms with just the SIEVE algorithm? As one spicy Czech saying goes: "To think means... to know nothing," so we'll go back to measuring on real data again. This time I compared the existing and new implementation with the maximum cache size set to 30 GB, which did not overflow during the twenty minutes of measurement. As can be seen in the image below, even if we did not run out of memory for the cache, there is a slight improvement in the performance of the entire DNS resolver when the cache is already largely full, i.e., in the second half of the test:
There is no observable difference in CPU usage, but in memory usage, we see that removing TTL-based cache cleaning leads to an increase in memory consumption. This is essentially fine, because the purpose of the cache is to store data, not to discard it preventively.

If you would like to implement SIEVE into your own systems, you can take a look at the implementation in Python, which Yazhuo Zhang presents in this blog. Alternatively, for an implementation in C, you can take a look at the Merge Request that implements the algorithm for BIND 9. The SIEVE project website lists other projects and libraries that use this new algorithm.
What's New from ISC

Last week, ICANN published a report on the importance of open source in the DNS.
Read post
It’s time to meet another of ISC’s engineers! This time, let’s get to know Włodek Wencel, our DHCP Quality Assurance Manager.
Read post